 AI
AI
Israeli researchers from Offensive AI Lab have published a paper describing a method for restoring the text of intercepted AI chatbot messages. Today we take a look at how this attack works, and how dangerous it is in reality.
What information can be extracted from intercepted AI chatbot messages?
Naturally, chatbots send messages in encrypted form. All the same, the implementation of large language models (LLMs) and the chatbots built on them harbors a number of features that seriously weaken the encryption. Combined, these features make it possible to carry out a side-channel attack when the content of a message is restored from fragments of leaked information.
To understand what happens during this attack, we need to dive a little into the details of LLM and chatbot mechanics. The first thing to know is that LLMs operate not on individual characters or words as such, but on tokens, which can be described as semantic units of text. The Tokenizer page on the OpenAI website offers a glimpse into the inner workings.
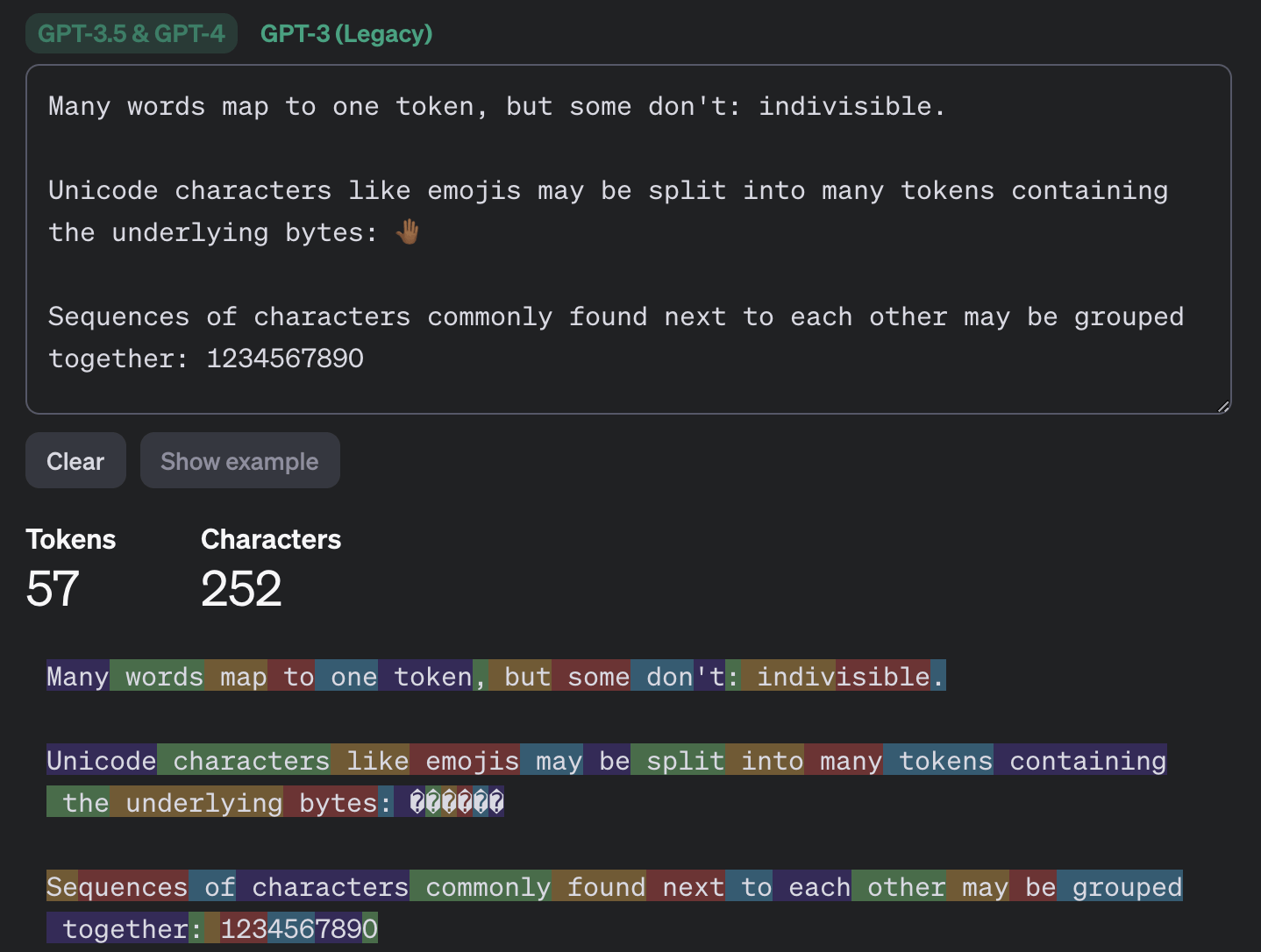
This example demonstrates how message tokenization works with the GPT-3.5 and GPT-4 models. Source
The second feature that facilitates this attack you’ll already know about if you’ve interacted with AI chatbots yourself: they don’t send responses in large chunks but gradually — almost as if a person were typing them. But unlike a person, LLMs write in tokens — not individual characters. As such, chatbots send generated tokens in real time, one after another; or, rather, most chatbots do: the exception is Google Gemini, which makes it invulnerable to this attack.
The third peculiarity is the following: at the time of publication of the paper, the majority of chatbots didn’t use compression, encoding or padding (appending garbage data to meaningful text to reduce predictability and increase cryptographic strength) before encrypting a message.
Side-channel attacks exploit all three of these peculiarities. Although intercepted chatbot messages can’t be decrypted, attackers can extract useful data from them — specifically, the length of each token sent by the chatbot. The result is similar to a Wheel of Fortune puzzle: you can’t see what exactly is encrypted, but the length of the individual words tokens is revealed.

While it’s impossible to decrypt the message, the attackers can extract the length of the tokens sent by the chatbot; the resulting sequence is similar to a hidden phrase in the Wheel of Fortune show. Source
Using extracted information to restore message text
All that remains is to guess what words are hiding behind the tokens. And you’ll never believe who’s good at guessing games: that’s right — LLMs. In fact, this is their primary purpose in life: to guess the right words in the given context. So, to restore the text of the original message from the resulting sequence of token lengths, the researchers turned to an LLM…
Two LLMs, to be precise, since the researchers observed that the opening exchanges in conversations with chatbots are almost always formulaic, and thus readily guessable by a model specially trained on an array of introductory messages generated by popular language models. Thus, the first model is used to restore the introductory messages and pass them to the second model, which handles the rest of the conversation.
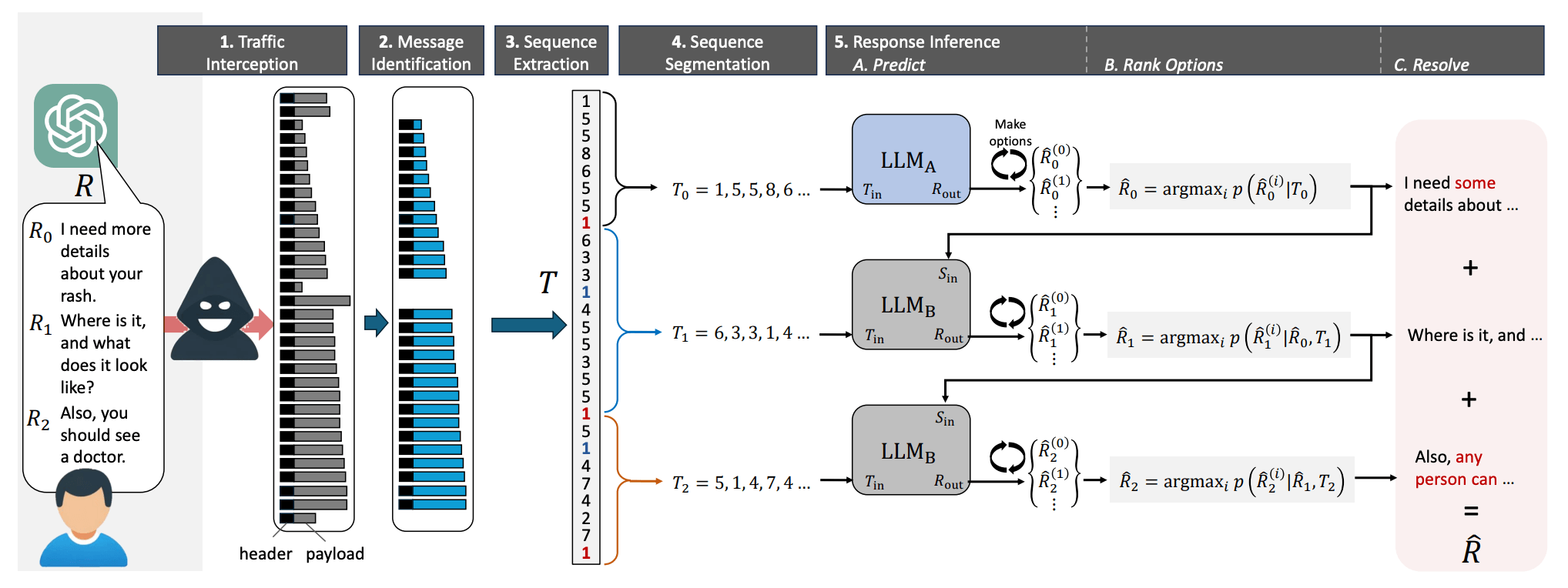
General scheme of the attack. Source
This produces a text in which the token lengths correspond to those in the original message. But specific words are brute-forced with varying degrees of success. Note that a perfect match between the restored message and the original is rare — it usually happens that a part of the text is guessed wrong. Sometimes the result is satisfactory:

In this example, the text was restored quite close to the original. Source
But in an unsuccessful case, the reconstructed text may have little, or even nothing, in common with the original. For example, the result might be this:

Here the guesswork leaves much to be desired. Source
Or even this:

As Alice once said, “those are not the right words.” Source
In total, the researchers examined over a dozen AI chatbots, and found most of them vulnerable to this attack — the exceptions being Google Gemini (née Bard) and GitHub Copilot (not to be confused with Microsoft Copilot).

At the time of publication of the paper, many chatbots were vulnerable to the attack. Source
Should I be worried?
It should be noted that this attack is retrospective. Suppose someone took the trouble to intercept and save your conversations with ChatGPT (not that easy, but possible), in which you revealed some awful secrets. In this case, using the above-described method, that someone would theoretically be able to read the messages.
Thankfully, the interceptor’s chances are not too high: as the researchers note, even the general topic of the conversation was determined only 55% of the time. As for successful reconstruction, the figure was a mere 29%. It’s worth mentioning that the researchers’ criteria for a fully successful reconstruction were satisfied, for example, by the following:

Example of a text reconstruction that the researchers considered fully successful. Source
How important such semantic nuances are — decide for yourself. Note, however, that this method will most likely not extract any actual specifics (names, numerical values, dates, addresses, contact details, other vital information) with any degree of reliability.
And the attack has one other limitation that the researchers fail to mention: the success of text restoration depends greatly on the language the intercepted messages are written in: the success of tokenization varies greatly from language to language. This paper was focused on English, which is characterized by very long tokens that are generally equivalent to an entire word. Hence, tokenized English text shows distinct patterns that make reconstruction relatively straightforward.
No other language comes close. Even for those languages in the Germanic and Romance groups, which are the most akin to English, the average token length is 1.5–2 times shorter; and for Russian, 2.5 times: a typical Russian token is only a couple of characters long, which will likely reduce the effectiveness of this attack down to zero.
-

- Texts in different languages are tokenized differently. An English sample

-

- Texts in different languages are tokenized differently. A German sample

-

- Texts in different languages are tokenized differently. A Russian sample

-

- Texts in different languages are tokenized differently. A Hebrew sample

At least two AI chatbot developers — Cloudflare and OpenAI — have already reacted to the paper by adding the padding method mentioned above, which was designed specifically with this type of threat in mind. Other AI chatbot developers are set to follow suit, and future communication with chatbots will, fingers crossed, be safeguarded against this attack.

 Tips
Tips